


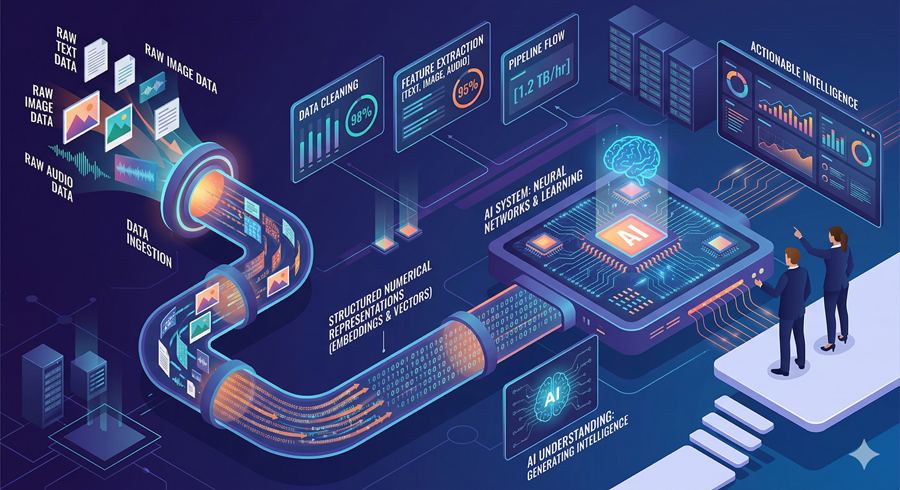
I used to think AI was just about typing a prompt and getting an answer. It felt almost magical. But once I started looking deeper, I realized it is not magic at all. It is math. A lot of math, layered in a way that turns simple operations into something that feels intelligent.
At its core, everything begins with the most basic concept in computing: ones and zeros. Every piece of data, whether it is text, images, or sound, gets converted into numbers that a machine can process.
From Data to Numbers
When I look at how AI processes something like an image, it becomes clearer. Each pixel is turned into a number, and those numbers form a grid called a matrix. Text is also converted into numerical representations. This transformation allows AI to work with data in a structured, mathematical way.
Once everything is converted, the system applies a series of mathematical operations like multiplication and addition. These operations might seem simple individually, but when combined across millions or billions of steps, they become powerful.
Neural Networks: The Core Engine
The real “brain” of AI is something called a neural network. I think of it as layers of interconnected nodes, each performing calculations on incoming data. The input enters the first layer, then passes through multiple hidden layers where the actual processing happens.
Each node multiplies inputs by weights, adds a bias, and then passes the result through a function that decides what information moves forward. These layers allow the system to detect patterns, whether it is recognizing objects in images or predicting the next word in a sentence.
How AI Learns From Mistakes
What makes AI useful is its ability to learn. After producing an output, the system compares it to the correct answer and calculates how wrong it was. This error is then sent backward through the network, adjusting the weights to improve future results.
This process, known as backpropagation, gradually improves performance over time. The system keeps updating itself, getting better with each cycle. The size of each adjustment is controlled carefully so the model learns efficiently without becoming unstable.
Making AI Faster and More Efficient
I also find it fascinating how AI is optimized to run on everyday devices. Techniques like normalization help stabilize learning and speed things up. Other methods randomly disable parts of the network during training so the system becomes more robust and does not rely too heavily on specific nodes.
There are also shortcuts like transfer learning, where models reuse knowledge from previous training instead of starting from scratch. This dramatically reduces the time and data needed to build useful systems.
From Training to Real-World Use
Once trained, models can be compressed using techniques like quantization, reducing their size while keeping most of their accuracy. This is why AI can run on phones as well as powerful computers.
There are also privacy-focused methods like federated learning, where models learn from data on devices without collecting that data centrally. At the same time, newer approaches allow AI to learn from raw, unlabeled data, making training more scalable.
Short Paragraph
What I take away from all of this is that AI is not a single breakthrough but a combination of mathematical ideas layered together. From simple binary data to complex neural networks, every step builds on the previous one, turning basic calculations into systems that can learn, adapt, and feel almost human in how they respond.