



For years, the rule of artificial intelligence seemed simple: bigger models win.
More parameters, more GPUs, and more training data often produced stronger systems. That formula has powered the rapid rise of modern AI. But a new model developed by Yuan Lab AI challenges that assumption unexpectedly.
Instead of simply building a larger system, researchers created a massive trillion-parameter model and then removed a large portion of it during training. The model, called Yuan 3.0 Ultra, began with more than 1.5 trillion parameters. During training, roughly one-third of those parameters were deleted.
Surprisingly, the model became more efficient while maintaining competitive performance against other advanced AI systems.
This result highlights an important shift in how future AI systems might be designed.
The Rise of the Mixture of Experts
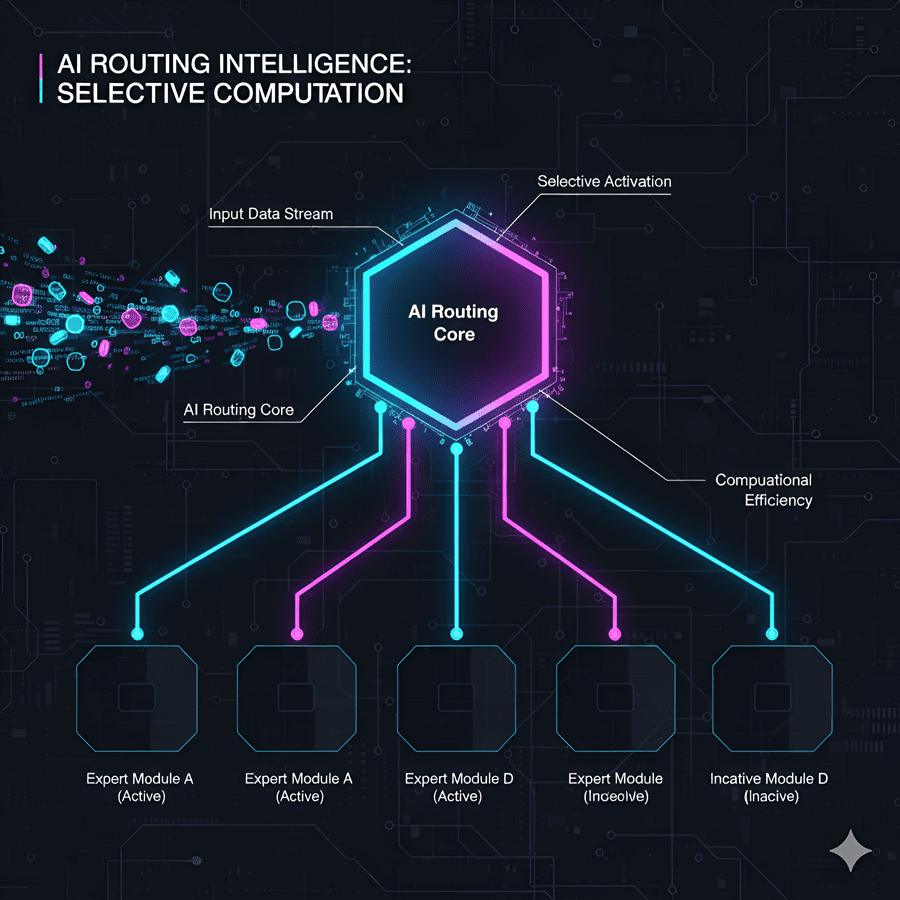
Yuan 3.0 Ultra uses an architecture known as a Mixture-of-Experts network.
Instead of one giant neural network handling every task, the system is divided into many smaller networks known as “experts.” Each expert focuses on certain patterns or types of information.
When text enters the model, it does not activate the entire network. Instead, a routing system selects only the experts who are most relevant to the task.
This approach works somewhat like a large company. Not every employee works on every project. Instead, work is directed to specialists who are best suited to solve the problem.
Because of this design, AI models can become extremely large without requiring the full system to run for every request.
Why Bigger Isn’t Always Better
During training, the researchers discovered something interesting. Even though the model contained over a trillion parameters, many of the experts were rarely used.
A small number of experts handled most of the workload, while others processed very little data.
Rather than forcing every expert to remain active, the team chose a different strategy. They removed the weakest ones.
The training system continuously monitored how frequently each expert was used. Experts who consistently handled very little work were gradually removed from the network.
By the end of training, about one-third of the original parameters had been pruned away. Counterintuitively, the system did not become weaker. It became more efficient and focused.
A Model That Learns What to Remove
The pruning process, called Layer-Adaptive Expert Pruning, happens while the model is still learning.
As training continues, the system identifies which experts contribute meaningful results and which remain mostly idle. Underperforming experts are removed layer by layer.
This process offers two major advantages.
First, the remaining experts become more specialized because they handle more relevant tasks. Second, the system becomes faster since fewer unnecessary computations are performed.
In the case of Yuan 3.0 Ultra, training efficiency improved dramatically after pruning and workload balancing were introduced.
A Different Direction for AI
The success of Yuan 3.0 Ultra suggests that the future of artificial intelligence may not depend only on building larger models.
Instead, progress may come from smarter architectures that use computing resources more efficiently. Removing weak components, strengthening specialized ones, and optimizing how systems run across hardware could matter just as much as increasing size.
In other words, the next generation of AI might not simply be bigger.
It may be better designed.