


The most important development in AI this week was not a flagship release. It was a structural challenge to one of the field’s oldest assumptions: that better models require more parameters.
What makes that interesting is not just the claim. It is that the alternative is increasingly plausible.
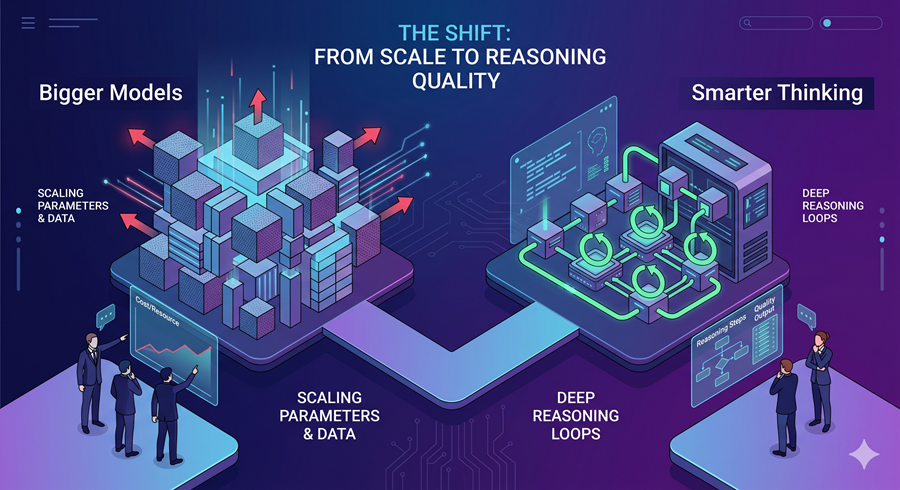
A new open-source project, Open Mythos, explores a different path. Instead of making models larger, it asks a more useful question: what if models improved by thinking longer rather than growing bigger?
The Case for Recurrent Reasoning
Most modern language models scale familiarly. More capability usually means more layers, more parameters, and more compute. Intelligence is treated as something you buy through size.
Open Mythos proposes a different architecture. Rather than stacking more layers, it reuses the same internal layers repeatedly during inference. The model loops through the same reasoning block multiple times, refining its internal state before producing an answer.
That shift matters because it changes the economics of intelligence. Instead of paying for more parameters, the system spends compute on deeper reasoning at runtime.
This is not just architectural novelty. It is a different theory of capability.
Why This Could Matter More Than Chain-of-Thought
What makes this approach more interesting is where the reasoning happens.
Most current systems simulate reasoning externally. They generate intermediate text, walk through the visible steps, and use chain-of-thought scaffolding to improve their outputs. It works, but it is inefficient and often performative.
Recurrent reasoning moves that process into latent space. The model does not write out its intermediate logic. It refines hidden representations internally, then returns a result.
That is a fundamentally different form of computation. It suggests better reasoning may come less from producing more tokens and more from allocating more internal thought.
If that holds, the next leap in model quality may come from inference design, not just training scale.
The Broader Shift Is Toward Efficient Intelligence
What makes this more than an isolated experiment is how closely it aligns with broader trends.
Across the frontier, the same pattern is emerging: mixture-of-experts routing, compressed attention, modular agents, and adaptive compute. Different labs are converging on the same conclusion. The future is not just larger models. It is more selective, more parallel, and more compute-efficient systems.
That matters because scaling is getting expensive. Efficiency is becoming strategic.
Why This Changes the Direction of AI
The most important implication is simple: AI may be entering a phase where intelligence is no longer defined primarily by parameter count, but by how effectively a model allocates reasoning.
That is a major shift.
If the next generation of systems gets better by thinking longer, routing smarter, and using compute more selectively, then the frontier will be shaped less by who can train the biggest model and more by who can design the most efficient one.